


Why AMD AI
Highest Compute Efficiency & Optimal Performance
Optimal AI Inference Performance
World‘s most advanced AI acceleration from edge to data center. Highest AI inference performance, fastest experience & lowest cost.

AI for Data Center
Delivering the highest throughput at the lowest latency for cloud-end image processing, speech recognition, recommender system accelerations, and natural language process (NLP) accelerations

AI for Edge
Superior AI inference capabilities to accelerate deep learning processing in self-driving cars, ADAS, healthcare, smart city, retail, robotics, and autonomous machines at the edge.
Special Limited Offer & AI Webinars
.jpg)
Data Center AI Acceleration
High-Throughput AI Inference

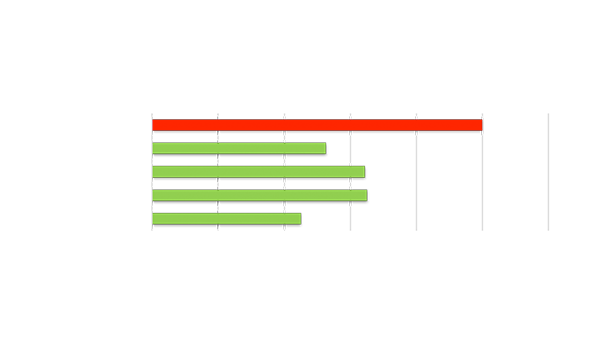
Highest Performance AI Inference
2X TCO reduction vs. mainstream GPUs
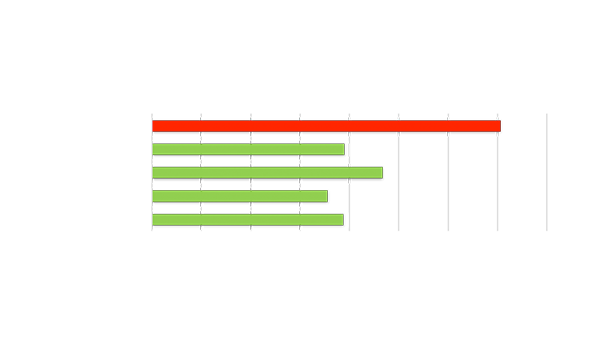

Highest Performance Video Analytics Throughput
2X number of video streams vs. mainstream GPUs
")
Simple Learning Curve
Popular AI models and frameworks with no hardware programming required

Graph Sources: https://developer.Nvidia.com/deep-learning-performance-training-inference
AMD Data Center AI Case Studies



Get Started with AMD Data Center AI Solutions



Purchase VCK5000
Purchase the VCK5000 Development Card for AI inference built on the AMD 7nm Versal adaptive SoC
Try VCK5000 on the cloud
Compute AI inference at high performance with Mipsology and achieve full video processing ML inference pipeline for AI recognition with Aupera
Download Vitis AI
Get started with AMD AI solutions and download the Vitis™ AI development environment
EDGE AI ACCELERATION
Industry-Leading Edge AI Acceleration Performance

Lowest Latency AI Inference
- Optimal FPS and power consumption on Zynq™ UltraScale+and Versal™
- Powerful deep learning processing units (DPU)
- State-of-the-art model optimization technologies; 5X to 50X model performance boost

Flexible Software Flow
- Support AI models from PyTorch, TensorFlow, and Caffe
- Easy C++ and Python-based libraries and APIs
- Unified quantizer, compiler, and runtime for deployment across edge platforms

Scalable & Adaptable
- Scalable DPU IP for different logic and AIE resources
- Open AI model zoo for free-on-board try-on
- Whole Application Acceleration
Latency Response Comparison

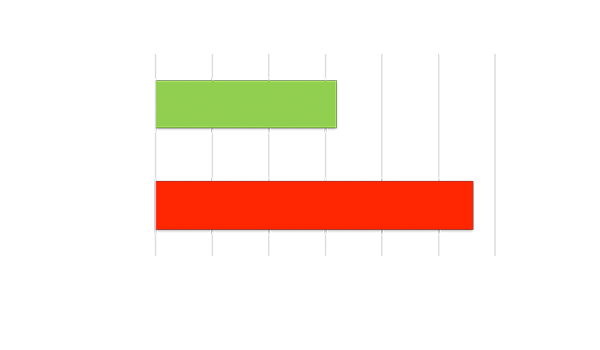
High Throughput OR Low Latency
Achieves throughput using high-batch size. Must wait for all inputs to be ready before processing, resulting in high latency.

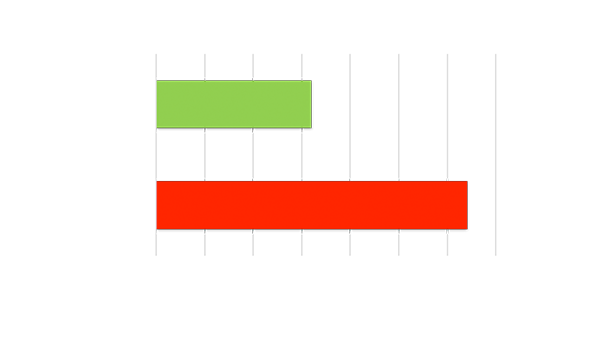
High Throughput AND Low Latency
Achieves throughput using low-batch size. Processes each input as soon as it’s ready, resulting in low latency.
Scalability to Fit All Your Edge Products

End-to-end application performance
Optimized hardware acceleration of both AI inference and other performance-critical functions is achieved by tightly coupling custom accelerators into a dynamic architecture silicon device.
This delivers end-to-end application performance that is significantly greater than a fixed-architecture AI accelerator. In such devices, the other performance-critical functions of the application must still run in software, without the performance or efficiency of custom hardware acceleration.


Get Started with AMD Edge AI Solutions



Purchase Kria KV260 Vision AI Starter Kit
Built for advanced vision application development without requiring complex hardware design knowledge
Download Vitis AI
Achieve efficient AI computing on edge devices for your applications with Vitis AI
Visit App Store
Pre-built applications for Kria system-on-modules! Evaluate, purchase, & deploy accelerated applications!
Explore AMD Solutions fo Edge AI Inference




Developer Resources

Visit App Store
Evaluate, purchase, & deploy accelerated applications!

Developer Site
Explore articles, projects, tutorials and more!

Stay Informed
Stay up to date with all AI Acceleration News